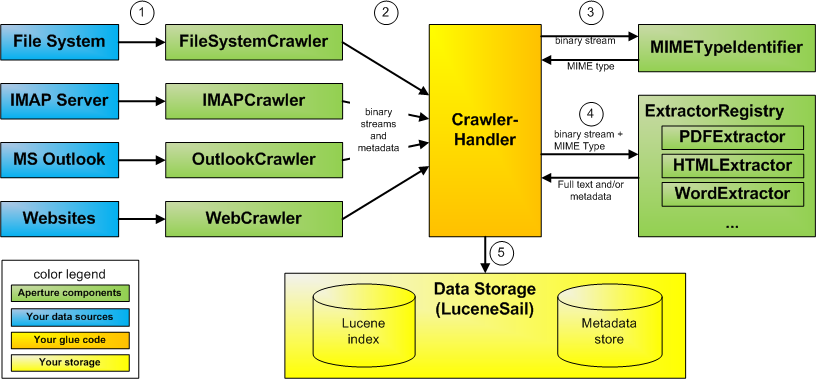
Aperture consists of a number of APIs each fulfilling a different type of service, e.g. text and metadata extraction, crawling data in a data source or identifying a file's MIME type. The code involved in implementing and managing such a service is typically organized in a particular way. Once you know how this structure works, you will be better able to quickly find your way around Aperture. The following image shows how the components work together in a typical application:
Aperture operates on existing data sources, many types are supported out of the box (like file-systems with files or IMAP servers), other may easily be added. For each of these data source types, Aperture provides a crawler, which reads data from the source and converts it to a standardized format - RDF. A the most basic level RDF is a data structure that stores information about various resources in a manner comparable to a Java Hashset, but with much more possibilities. The resources can be linked with each other into a network. Moreover RDF gives a well-specified meaning to each piece of data that allows it to be used by all RDF-aware applications You should really get acquainted with the power of RDF in order to make full use of Aperture. The rest of this tutorial assumes that you are familiar at least with the basic concepts like graph, triple, URI, literal etc. Please refer to the RDF homepage for more details and pointers to further reading.
Once the data is converted by the crawler, it is passed to a crawler handler. The crawler handler is the component you will write to use Aperture in your application. You, as Aperture user, decide now what happens with the data.
When the crawler finds a file (like a HTML document), you can use Aperture to extract metadata and the full text from it. To do this, you need to take following steps.
Aperture architecture is built from services. This makes it fit nicely in other service-oriented applications. The main services are:
The heart of each service is an API, usually a Java interface, whose methods perform the embodied service. For example, the Extractor interface defines an extract method that performs full-text and metadata extraction on an InputStream accessing a document of a specific MIME type. A specific implementation such as HtmlExtractor implements this service for HTML documents.
Each service API is generally accompanied by a factory API, such as ExtractorFactory. Each API implementation should come with a factory implementation. The purpose of this factory is twofold:
For example, ExtractorFactory defines a getSupportedMimeTypes method that returns the set of MIME types supported by a particular Extractor implementation. Also, it defines a get method that returns an Extractor instance ready for use. ExtractorFactory does not specify whether a new or shared instance is returned, that is up to the implementor to decide. HtmlExtractorFactory's getSupportedMimeTypes method returns a set containing "text/html" and other known HTML(-like) MIME types and returns a new HtmlExtractor on each get() invocation.
When implementing, you should take care that implementations of the factory are as light-weight as possible. Any expensive initialization operations needed for a service implementation should happen during the get operation or in some other kind of lazy way.
In order to keep track of all available implementations of a service, a registry is used. For example, ExtractorRegistry serves as a container for all known ExtractorFactories. When asked for all factories supporting a specific MIME type, you will get a set of all ExtractorFactories whose supported MIME type contain the specified MIME type. You can then use additional measures to select the best one or simply take the first one available.
This service-factory-registry approach has been inspired by OSGi, a platform for building component-oriented Java applications. It enables new factories to be added at runtime. (In OSGI it can be implemented by bundling new factories in separate bundles and registering them as services on startup. This feature could also be explored in "normal" desktop applications.) When a new factory is registered in a registry - any application using the registry will now transparently begin to use the new factory. That's the reason why factory instantiation should be as cheap as possible, as they may all be instantiated during startup.
For 'normal' java applications, not based on OSGi, a default implementation of a registry is also available. For example, DefaultExtractorRegistry contains an instance of every ExtractorFactory available in Aperture. When you want to use a different set, e.g. because you have your own set implementations, you can:
The image below shows an overview of the APIs and their dependencies of the Extractor example:
