The LinkExtractor interface defines a service for extracting hypertext links and other references to external resources from a document. Although it is primarily meant to be used by the WebCrawler class, it may also be of use for other applications as well and has therefore been kept separate from WebCrawler.
The link extractor classes are summarized in the following diagram:
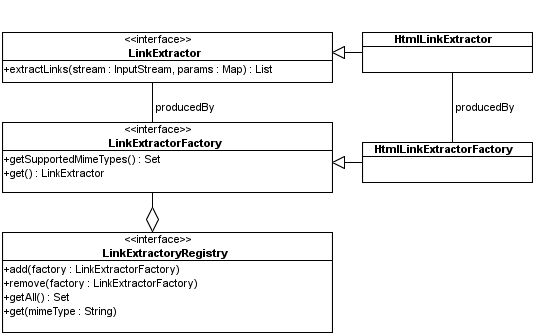
Currently only an implementation for HTML documents is available. In the future this may be extended with implementations for MS Office, OpenOffice, PDF, SGML, Flash and any other kind of format that has such links.
Depending on the types or links supported by the document format, LinkExtractors may differentiate between navigational links and embedded resources. Navigational links are those links that are specifically navigatable by a user, e.g. hyperlinks in a HTML document. Such links need to be extracted when crawling and indexing a website. When embedded resources are also included, all images, movies, sounds, stylesheets and other kinds of resources that are not explicitly hyperlinked but are automatically embedded in a document are also retrieved. This is useful when crawling a website in order to obtain a local copy of it.